How do you cut agent cost per turn without losing correctness? In a word — boundaries.
Two disclosures before anything else. First: every bracketed number in this piece is a slot waiting for a real value from my dashboard; I'd rather show you an honest blank than a fake decimal. Second: the one number that needs no slot — 15 — is just the count of jobs in the schema below. You can recount it yourself.
This is the story of one agent: my TokenMaxer publishing agent — [ONE-LINE DESCRIPTION: what it researches, drafts, fact-checks, and publishes]. Everything in this piece happened to that agent, or will be marked as a slot until I can prove it did.
Why frameworks win demos and lose production #
Start with the incentives, because the tactics fall out of them.
A framework vendor is rewarded for adoption. Adoption is maximized by one import that bundles everything: the loop, the tool model, the memory shape, the permission system, the tracing story. LangGraph, CrewAI, AutoGen, the OpenAI Agents SDK, the Claude Agent SDK — the bundle is the product. That's not a criticism. It's the reward function.
Your production system is rewarded for something else entirely: replaceability. The provider API rewards stable prompt prefixes with cheap cached tokens. Your debugger rewards first-class event logs. Your security review rewards permission logic it can read as code. None of those rewards flow to "I imported the bundle."
So the framing I use is this:
Here's the one mental model I'll lean on for the whole piece: the model is the CPU; the harness is the operating system. Nobody confuses buying a CPU with having a computer. The CPU is brilliant and useless without a scheduler, a memory layout, permission bits, process isolation, and a syslog. When you import a framework wholesale, you're not buying a CPU — you're flashing someone else's entire OS image and hoping their scheduler fits your workload forever.
Use the SDKs as raw material. The Claude Agent SDK exposes the agent loop, tools, and context management behind Claude Code as a Python and TypeScript library. The OpenAI Agents SDK organizes production agent work around agents, handoffs, guardrails, sessions, tracing, and tools. Strong primitives. But primitives are the CPU, not the OS.
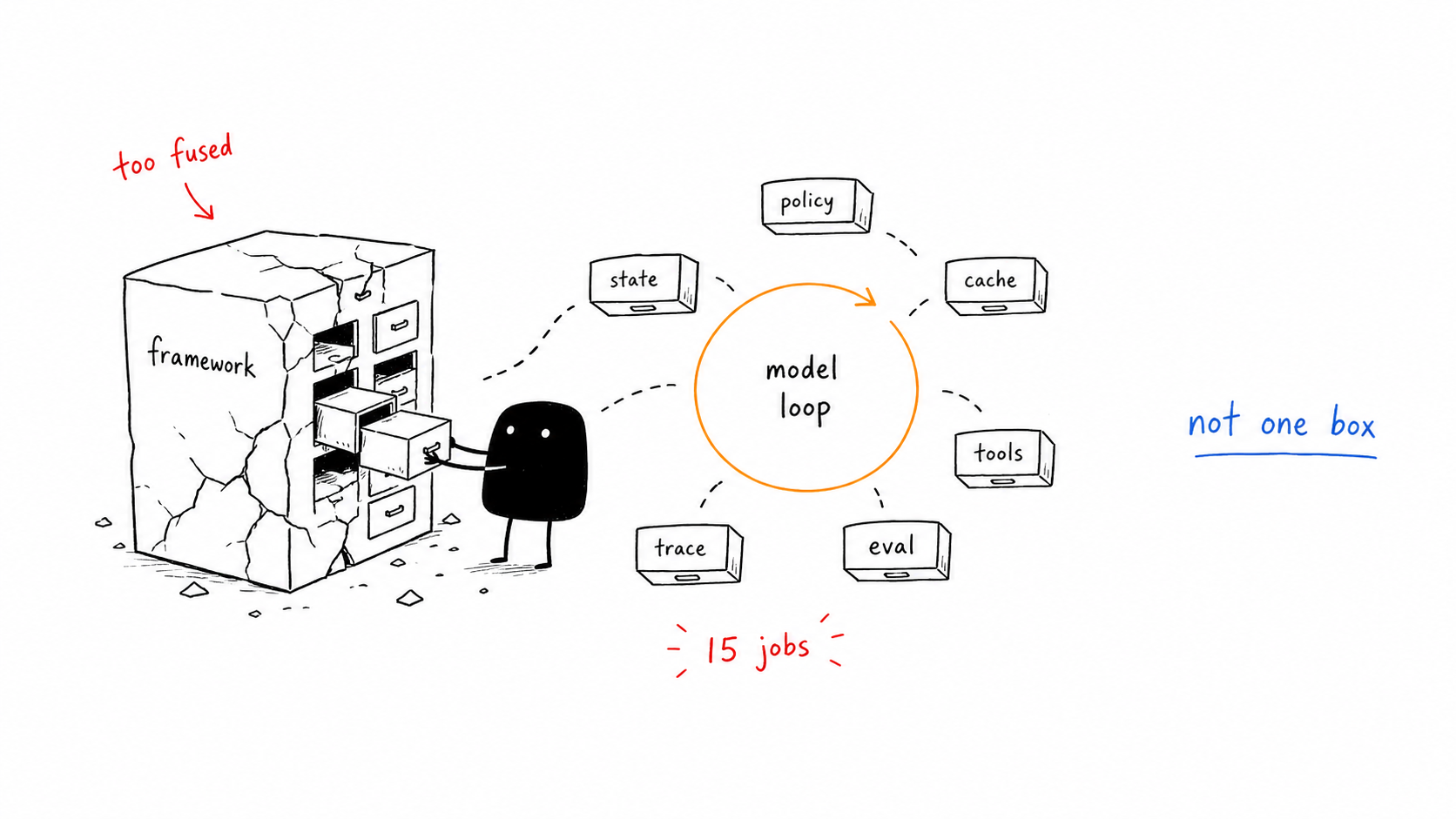
Starting point / Results #
The before state, with the same precision I'd demand of the after state:
Before:
- Architecture: [DESCRIBE: the request-handler version — build prompt, call model, run tools, store final text]
- Cost per turn: [YOUR BEFORE METRIC]
- Cache read tokens per turn: [YOUR BEFORE METRIC]
- Debugging a failed run meant: [HOW LONG transcript archaeology took, with one concrete example]
After:
- Cost per turn: [YOUR AFTER METRIC]
- Cache read tokens per turn: [YOUR AFTER METRIC]
- Eval pass rate: [GUARDRAIL METRIC — must be at or above the before baseline]
- Time to root-cause a failed run: [YOUR AFTER METRIC]
Two rules before you judge any of these numbers — mine or yours:
- Guardrail rule. Cost per turn is the win metric. Eval pass rate is the guardrail. If pass rate drops below [YOUR BASELINE] while cost falls, the win doesn't count. A cheaper wrong answer is a more expensive product.
- Sample size rule. Don't conclude anything about a cache layout or policy change before [N TURNS — pick a threshold on the order of a few hundred] turns. Agent traffic is lumpy; small samples lie.
And one dead end, admitted up front: [WAR STORY: the version where I imported one framework wholesale — which one, what layer didn't fit, what the wrapper-around-the-wrapper looked like, and what forced the rebuild].
The 15 jobs #
Here is the decomposition I rebuilt around:
The point is not that you need exactly 15 services. The point is the architecture test:
The method below is how I built those jobs in dependency order, on one agent. Scale the structure later — more on that at the end.
Step 1: Make the turn the unit of work #
- Persist every turn request before the model ever sees it.
- Append every event — tool call, approval, cost, artifact — to a turn-keyed log.
- End every turn in an explicit state: done, error, paused-for-approval, budget-stopped, or handed off.
This is the OS scheduler. A turn starts when a user, webhook, or background job asks the agent for something, and it ends in a named state — never "the handler returned."
The loop itself is not the hard part. The Claude Agent SDK loop docs describe the cycle directly: receive a prompt, evaluate, request tools or answer, execute tools, feed results back, repeat. Let the SDK run that treadmill. What the SDK won't do is wrap it in a lifecycle:
- accept the turn
- persist the request
- resolve user, workspace, provider, model, tools, budget, and permission mode
- assemble context
- run the model loop
- stream events to the UI
- gate every tool call
- write tool, policy, cost, cache, and trace events
- persist artifacts and result
- verify the changed thing
For my publishing agent, a turn is "draft the section on X" or "fact-check this claim" — and when one fails, I need to know what context was assembled, which tools were visible, what was approved, and what changed in the world.
Decision rule: if you can't answer "what exactly was visible to the model on turn N" from storage alone — no transcript spelunking — the turn store isn't done. Don't move to step 2 until you can.
Step 2: Lay out context for the cache #
- Put tool definitions and system rules first, and never mutate them mid-session.
- Push timestamps, scratch notes, and fresh facts into the message layer.
- Track cache-read and cache-creation tokens on every single turn.
This is the OS memory layout, and the provider priced it for you. Anthropic's prompt caching docs state the mechanical fact: caching references the full prompt prefix across tools, system, and messages, in that order, up to a cache breakpoint. The cost tracking docs add the operator signal: usage reports cache creation and cache read tokens, and the SDK applies prompt caching automatically for repeated content.
That pricing structure makes context layout an architecture decision, not a cost trick you bolt on later.
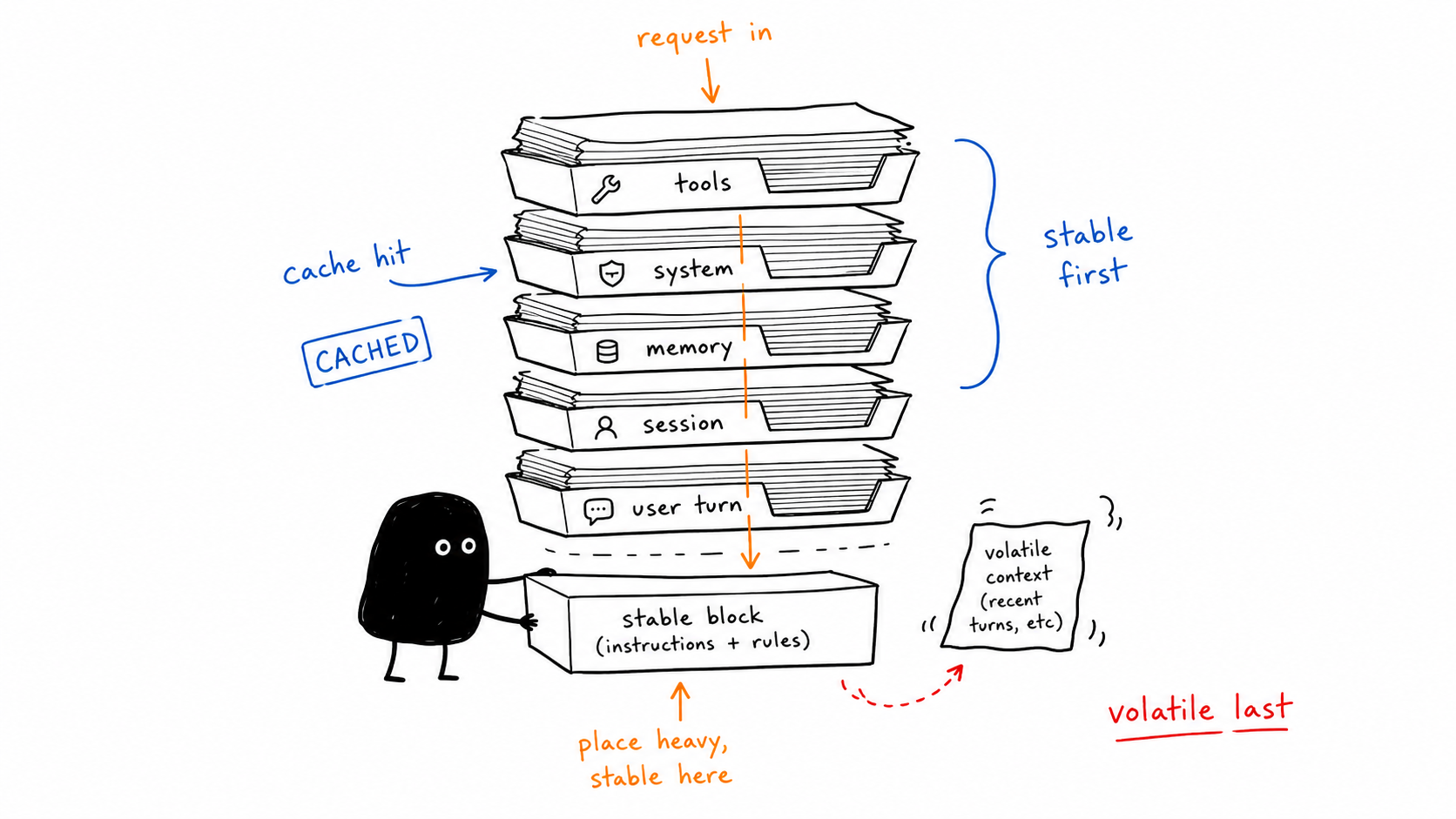
My publishing agent's layout:
Things that poison the stable prefix: live timestamps, randomized tool ordering, constantly rewritten memory, per-user scratch notes. Things that poison accuracy: dumping a giant tool catalog every turn. The tool search docs put numbers on this — tool definitions can eat 10-20K tokens for 50 tools, and selection accuracy degrades when too many are loaded at once. Tool search withholds definitions and loads a few on demand.
Decision rule: if cache-read tokens per turn drop after a deploy, treat it as a regression and bisect the prompt builder — something volatile leaked into the stable prefix. And remember the guardrail pair: cache hit rate up means nothing if eval pass rate fell.
Step 3: Write tool policy as code, not advice #
- Classify every tool by what it can break, not by what it's named.
- Block deterministic bad actions in hooks, before execution.
- Route every unresolved case to a human, with the decision and reason recorded.
These are the OS permission bits. The dangerous part of agents isn't weird text — it's that they do things. A read tool wastes tokens. A write tool can corrupt a repo. A publish tool can ship the wrong build to a live URL. Those differences must exist in code, not in a system-prompt paragraph saying "be careful."
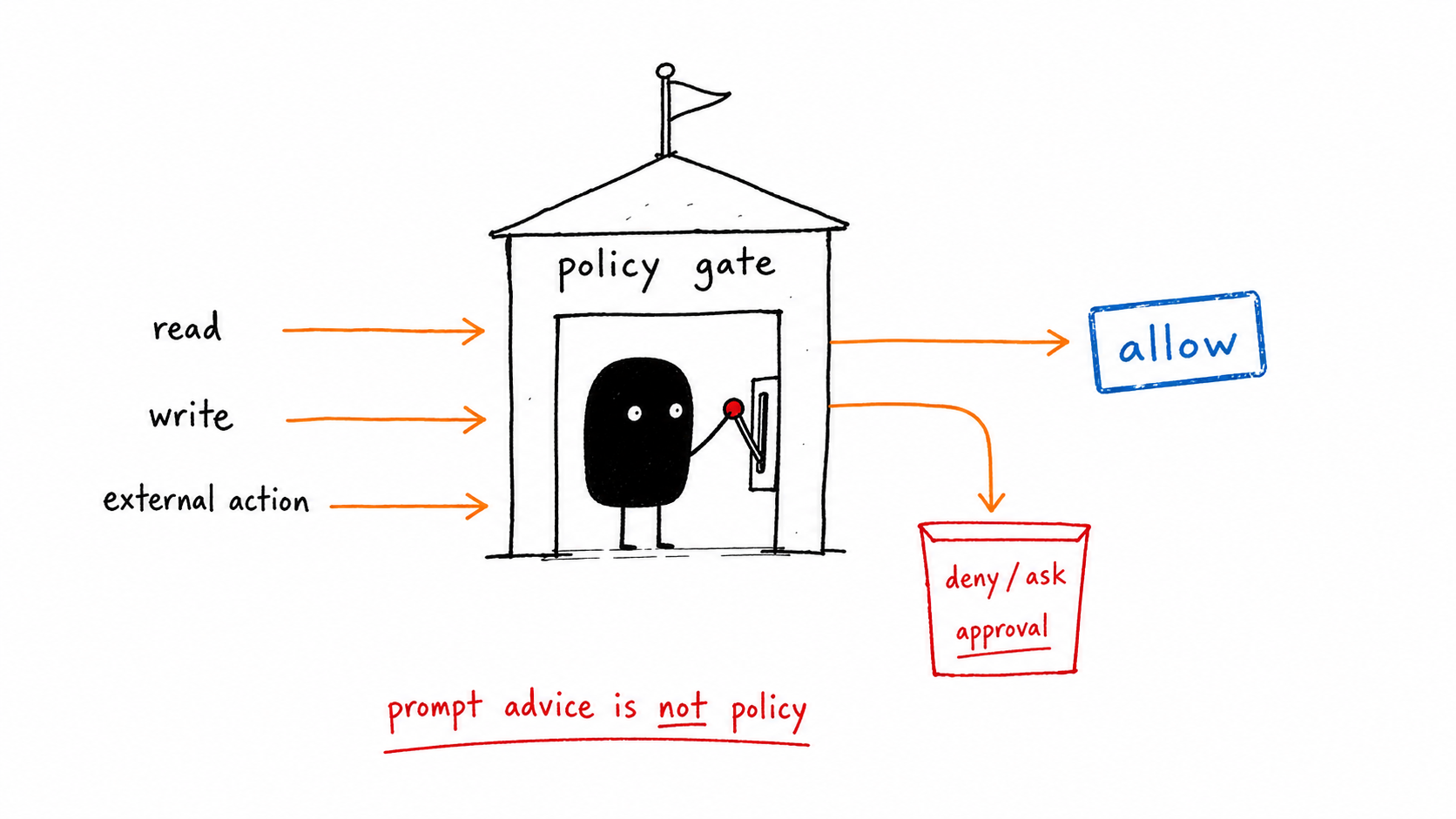
My risk classes:
- read-only
- usually auto-run with logging
- local mutation
- patch/edit/write with workspace policy
- shell execution
- classify by command, not just by tool name
- external mutation
- publish, deploy, send, update, charge, delete
- privileged browser/API
- audit trail, scope, and explicit workflow gate
The Claude Agent SDK gives you real control points — hooks, deny rules, permission modes, allow rules, and a canUseTool callback for unresolved cases. The docs also warn that allowed_tools pre-approves tools but is not, by itself, a hard sandbox in every mode; for a locked-down headless agent they recommend pairing explicit allowed tools with dontAsk. See Configure permissions and Handle approvals and user input. The hooks docs position hooks as exactly the place for blocking dangerous operations, logging, transforming inputs, and requiring approval.
A minimal shape:
READ_ONLY = {"Read", "Grep", "Glob", "WebFetch"}
BLOCKED_SHELL = ("rm -rf", "git reset --hard", "curl | sh")
async def approve_tool(tool_name, tool_input, context):
if tool_name in READ_ONLY:
return allow()
if tool_name == "Bash" and any(pattern in tool_input.get("command", "") for pattern in BLOCKED_SHELL):
return deny("Destructive shell command blocked.")
return ask_user("This tool can change state. Approve it?")Decision rule: auto-approve only read-only tools; anything that mutates external state gets a recorded gate, no exceptions. Win metric: auto-approval rate (fewer interruptions). Guardrail: incidents requiring rollback. If rollbacks rise as auto-approvals rise — [YOUR INCIDENT THRESHOLD] is the override — tighten the classes, don't celebrate the smoothness.
Step 4: Split conversation state from world state #
- Store conversation history — prompts, tool calls, results — in the session manager.
- Store files, URLs, database writes, and publish status in an artifact tracker.
- Link every artifact to the turn that created it.
The session docs are explicit about the boundary: a session persists the conversation history — prompt, tool calls, tool results, responses. It does not persist filesystem state; for file changes, the SDK points to separate checkpointing.
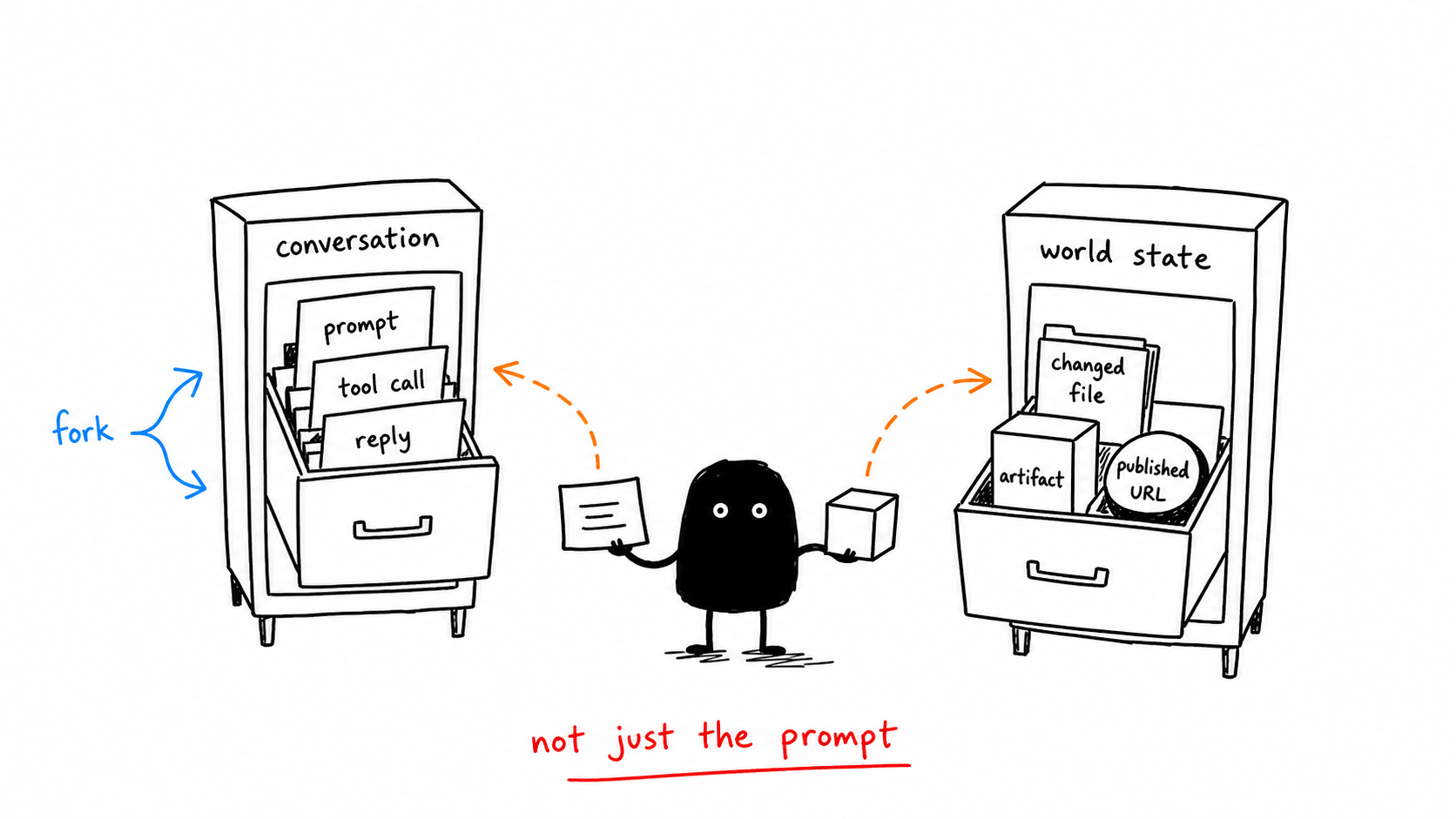
Conversation state answers: what did the user ask, what did the model say, which tools ran, what shaped the run. World state answers: what files changed, what rows changed, what got published, what URL now exists.
For my publishing agent this means sources, drafts, image files, fact-check findings, publish payloads, and live URLs all live as structured artifacts the prompt can reference. The prompt is not the database.
Decision rule: if rolling back a run requires rereading the transcript to figure out what changed, your world state isn't tracked. The artifact log, not the conversation, must be sufficient to undo a run.
Step 5: Use subagents for privilege separation; treat skills like code #
- Give each subagent only the tools its job needs — research can't write, the publisher can't browse.
- Send context-heavy side quests to an isolated agent and return only the distilled result.
- Version every skill file, give it an owner, and test it against fixtures.
Subagents get sold as a parallelism trick. The bigger value is isolation — these are the OS processes. The subagent docs say subagents run in fresh conversations, keep intermediate tool calls out of the parent context, can be restricted to specific tools, and can override model choice.
In my harness: a research subagent has search and read tools but no write access. A verifier runs browser checks. A publisher can only package approved artifacts and call the publish endpoint. That's privilege separation, and it also protects the cache layout from step 2 — an exploratory side quest doesn't bloat the parent's stable prefix.
Skills are the matching extension surface. The skills docs describe them as filesystem artifacts — SKILL.md files discovered from user and project directories and loaded when relevant. A bad skill is not harmless documentation; if it teaches the wrong API or skips an approval gate, the agent repeats the mistake with confidence. So: versioned, owned, tested, retired when stale, small enough to audit — and the harness records which runs used which skill versions.
Decision rule: spawn a subagent whenever a subtask needs a different context budget, tool scope, model, risk profile, or evaluation standard. Any one of those mismatches is sufficient cause. Don't spawn one for vibes.
Step 6: Emit a trace for every turn, and gate the irreversible stuff #
- Emit one trace per turn, with child spans for model, tool, hook, and eval events.
- Record allow/deny/ask for every tool decision, with the reason.
- Put product-specific eval checks in front of every irreversible action.
This is the syslog plus the final permission check before anything leaves the machine. The observability docs describe OpenTelemetry traces, metrics, and log events for model requests, tool execution, hooks, token counters, and session attributes. The OpenAI Agents SDK exposes tracing as a core surface too.
Per turn, my harness emits:
When a run goes wrong, the question is always one of: bad reasoning, bad tool data, missing context, wrong permission gate, broken cache layout, stale skill, or weak verification. Without this telemetry you're guessing between seven hypotheses. With it, you're reading.
Decision rule: if you can't reconstruct a failed run from telemetry alone — without rerunning it — instrumentation isn't done. And nothing irreversible (publish, deploy, charge, send) executes until the eval gate passes: for my publishing agent that's [YOUR EVAL CHECKS: fact-check pass, link verification, payload diff approval].
Do this on one agent first #
Don't decompose your whole fleet. I did this on one agent — the publishing agent — because [WHY THIS AGENT: share of traffic/cost/risk it carried]. Solve the structure where most of the cost and risk lives, prove the before/after numbers there, then scale the structure to the other agents. The 15 jobs transfer; the tuning doesn't.
And pick the substrate per product. The Claude Agent SDK may be the right CPU for Claude-native, local-workflow agents — it brings Claude Code's loop, tools, permissions, hooks, sessions, subagents, skills, cost tracking, and telemetry into a library. The OpenAI Agents SDK may be right when you want OpenAI-native agents, handoffs, guardrails, and tracing. Fine. Pick the CPU per product. Keep the OS yours.
Build checklist #
Before trusting this harness with real work, I check:
- [ ] Is the turn lifecycle explicit: accept, persist, assemble, run, gate, stream, verify, persist?
- [ ] Does context assembly separate stable and volatile layers?
- [ ] Are cache read and cache creation tokens tracked per turn?
- [ ] Is tool policy executable code, not prompt advice?
- [ ] Are read-only, local mutation, shell, external mutation, and privileged tools gated differently?
- [ ] Do hooks block deterministic bad actions before execution?
- [ ] Can a human approval pause and resume the same turn with the decision recorded?
- [ ] Are sessions, forks, checkpoints, artifacts, and external state changes distinct?
- [ ] Are subagents used for isolation, with minimal tool scopes?
- [ ] Are skills versioned, owned, and tested?
- [ ] Does every turn emit trace, cost, cache, policy, tool, and eval events?
- [ ] Are publishing, deployment, and database writes behind final eval gates?
Where this landed #
Restating the honest version of the results: cost per turn went from [YOUR BEFORE METRIC] to [YOUR AFTER METRIC] over [N TURNS] turns, with eval pass rate holding at [GUARDRAIL VALUE] — and if that guardrail hadn't held, none of this would count. The rebuild took [HONEST DURATION], most of it spent on [HARDEST JOB — my guess going in was wrong: it was X, not Y].
The data on cost and cache behavior I'm confident about; why the layout change moved the numbers as much as it did, I'm less sure — my theory is the stable prefix discipline, but I haven't isolated it from the tool-search change.
If you've decomposed a harness differently — fewer jobs, different boundaries, a job I'm missing — I want to see your schema. Compare notes.
Sources #
- Claude Agent SDK overview: agent loop, built-in tools, context management, Python and TypeScript library surface.
- How the Claude Agent SDK loop works: prompt, evaluate, execute tools, repeat, and result lifecycle.
- Anthropic prompt caching: prompt prefix caching across tools, system, and messages.
- Claude Agent SDK cost tracking: per-step usage, cache read tokens, cache creation tokens, and cost estimates.
- Claude Agent SDK tool search: dynamic tool discovery for large tool catalogs.
- Claude Agent SDK permissions: hooks, deny rules, permission modes, allow rules, and
canUseTool. - Claude Agent SDK user input and approvals: approval flows and pausing for human decisions.
- Claude Agent SDK hooks: callbacks for blocking, logging, transforming, approval, and lifecycle events.
- Claude Agent SDK sessions: continue, resume, fork, and the distinction between conversation and filesystem state.
- Claude Agent SDK subagents: isolated context, parallelism, tool restrictions, specialized instructions, and model overrides.
- Claude Agent SDK skills: filesystem skills, discovery, filtering, and SDK loading behavior.
- Claude Agent SDK observability: OpenTelemetry traces, metrics, log events, and span names.
- OpenAI Agents SDK documentation: agents, handoffs, guardrails, sessions, tracing, tools, and context strategies.
- OpenAI Agents SDK tracing: tracing as a core operational surface.